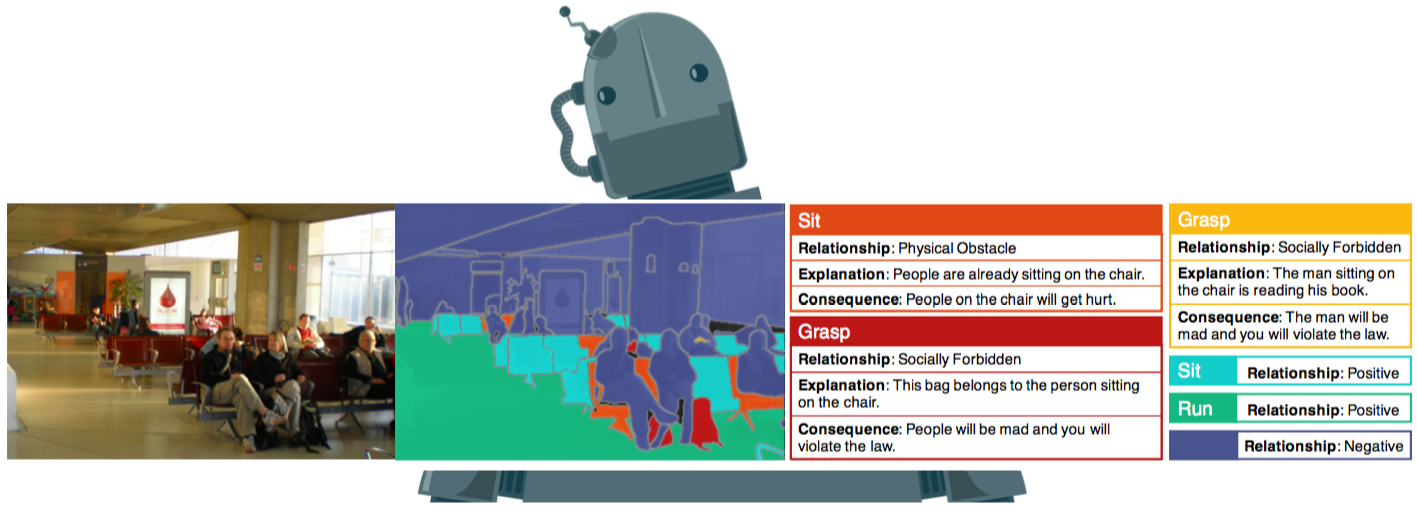
We address the problem of affordance reasoning in diverse scenes that appear in the real world. Affordances relate the agent's actions to their effects when taken on the surrounding objects. In our work, we take the egocentric view of the scene, and aim to reason about action-object affordances that respect both the physical world as well as the social norms imposed by the society. We also aim to teach artificial agents why some actions should not be taken in certain situations, and what would likely happen if these actions would be taken. We collect a new dataset that builds upon ADE20k, referred to as ADE-Affordance, which contains annotations enabling such rich visual reasoning. We propose a model that exploits Graph Neural Networks to propagate contextual information from the scene in order to perform detailed affordance reasoning about each object. Our model is showcased through various ablation studies, pointing to successes and challenges in this complex task.

ADE-Affordance Dataset

we collected a new dataset which we refer to as the ADE-Affordance dataset. We build our annotations on top of the ADE20k. Our dataset contains images from a wide variety of scene types, ranging from indoor scenes such as airport terminal or living room, to outdoor scenes such as street scene or zoo. It covers altogether 900 scenes, and is a good representative of the diverse world we live in. Furthermore, ADE-Affordance has been densely annotated with object instance masks and corresponding affordance, forming likely one of the most comprehensive datasets to date.
In particular, the affordance between an action and a object includes the following information:
- Relationship: categorize the relationship between an object and an action
- Explanation: explain the reason why the action cannot be taken
- Consequence: foresee the (negative) consequence if action was to be taken
Each folder contains affordance annotation separated by scene category (same scene categories than the ADE20K). The original image and segmentations can be downloaded here. For each image, the relationships for each object action pair are stored in .txt files. Explanations and consequences are stored in .json files.
- *.txt: Text files describe the relationship between an object and an action. In each line in the text file, there's a 3-digit number follow by 3 single-digit numbers (ex: 015 # 3 # 4 # 0). The first number correspong to the object id in original ADE20K instance mask. The following 3 numbers correspond to the relationship categories with respect to sit, run, and grasp in order.
- *.json: Only those images contain exception will have corresponding json files. The hierarchical structure of the dictionary in each json file is "action - object_id - explanation_and_consequence".
Due to the somewhat subjective flavor of the task, we collected annotations from three workers per image for our test subset of the dataset, allowing more robust evaluation of performance. In each line in the testing text file, we use the vertical bars to separate the gt annotated by different annotators. (ex: 015 # 3 # 4 # 0 | # 3 # 3 # 0 | # 4 # 6 # 0) In json files, three gt explanation/consequences are concatenated as a list.
Note that the object id in our dataset is exactly the same as in ADE20K dataset. We can directly combine the object class or instance segmentation map in ADE20K dataset for further model training. We also provide a list of file pathes in "file_path" directory which can link the image id we selected for ADE-Affordance to the original path in ADE20K dataset
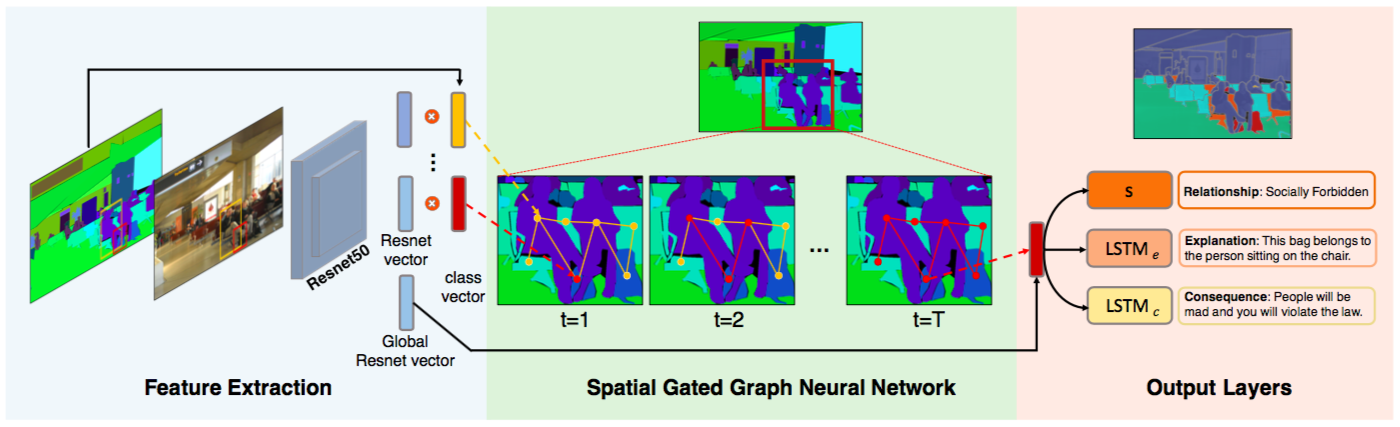
Spatial Gated Graph Neural Network
Reasoning about the affordances thus requires both, understanding the semantic classes of all objects in the scene, as well as their spatial relations. We propose to model these dependencies via a graph. The nodes in our graph indicate objects in the image, while the edges encode the spatial relations between adjacent objects. We adopt the GGNN framework to predict and explain affordances. We refer to our method as Spatial GGNN since our graph captures spatial relations between objects to encode context.
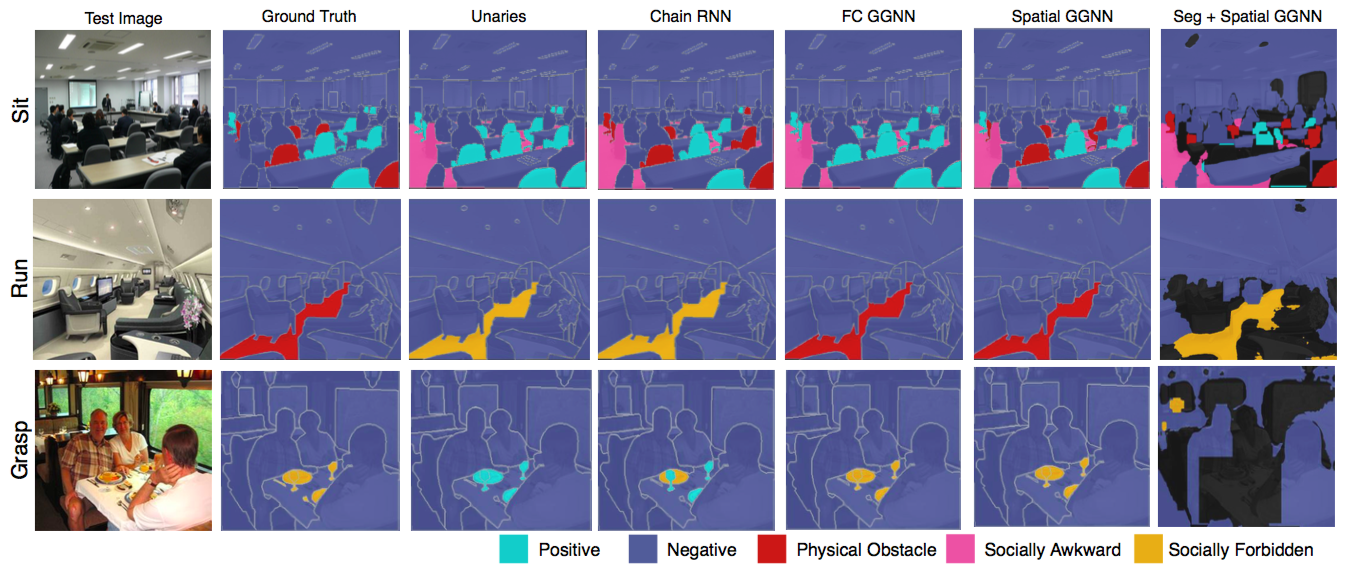
Qualitative Results

Citation
Bibilographic information for this work:
C.-Y. Chuang, J. Li, A. Torralba, and S. Fidler. "Learning to Act Properly: Predicting and Explaining Affordances from Images." arXiv, 2017. [PDF]
@article{cychuang2017learning,
title={Learning to Act Properly: Predicting and Explaining Affordances from Images},
author={Chuang, Ching-Yao and Li, Jiaman and Torralba, Antonio and Fidler, Sanja},
journal={arXiv preprint arXiv:1712.07576},
year={2017}
}
Last Update: Dec 5th, 2017 |