CAD Models
People
Code
Download the visualization + simple annotation code (12.5Mb)
Data
 View Dataset
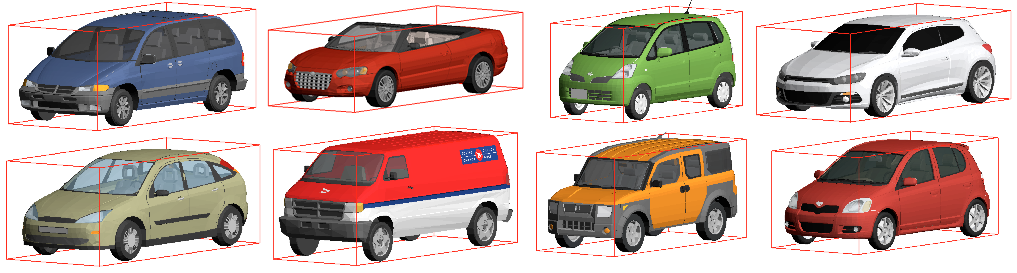
View DatasetThe CAD models were downloaded from Google's 3D Warehouse. A tight 3D box was fit around each object. The orientation was annotated by clicking on the front and ground face of the box. All cars were roughly aligned to have orientation 0 (front face facing the camera) and length of 1.8m. For most cars we also provide information about the specific make of the car (e.g., Volkswagen-Golf) and real-world dimensions (obtained online from car manufacturers). Note that the cars files include vans, cabriolets, and even a few formula 1. Functions for annotation and visualization (in matlab) are provided in the code. There may be some duplicate models (same model, but e.g. different color of the object).
- Download the CAD models for cars (234Mb). There are 183 models. Original Sketchup files are here
- Download the CAD models for beds (57Mb). There are 193 models.
- Download the CAD models for sofas (76Mb). There are 281 models.
- Download the CAD models for tables (24Mb). There are 86 models.
Contact
For questions regarding the data please contact Sanja Fidler.
Relevant Publications
If you use the data please cite the following publication:
-
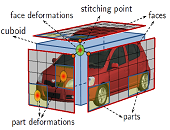
3D Object Detection and Viewpoint Estimation with a Deformable 3D Cuboid Model (spotlight presentation)
Sanja Fidler, Sven Dickinson, Raquel Urtasun
Neural Information Processing Systems (NIPS), Lake Tahoe, USA, December 2012
800 CAD models registered to canonical viewpoint available!
Paper Abstract Bibtex
@inproceedings{FidlerNIPS12,
author = {Sanja Fidler and Sven Dickinson and Raquel Urtasun},
title = {3D Object Detection and Viewpoint Estimation with a Deformable 3D Cuboid Model},
booktitle = {NIPS},
year = {2012}
}This paper addresses the problem of category-level 3D object detection. Given a monocular image, our aim is to localize the objects in 3D by enclosing them with tight oriented 3D bounding boxes. We propose a novel approach that extends the well-acclaimed deformable part-based model [1] to reason in 3D. Our model represents an object class as a deformable 3D cuboid composed of faces and parts, which are both allowed to deform with respect to their anchors on the 3D box. We model the appearance of each face in fronto-parallel coordinates, thus effectively factoring out the appearance variation induced by viewpoint. Our model reasons about face visibility patters called aspects. We train the cuboid model jointly and discriminatively and share weights across all aspects to attain efficiency. Inference then entails sliding and rotating the box in 3D and scoring object hypotheses. While for inference we discretize the search space, the variables are continuous in our model. We demonstrate the effectiveness of our approach in indoor and outdoor scenarios, and show that our approach significantly outperforms the state of-the-art in both 2D and 3D object detection.