Reference
This lecture loosely follows chapter 1 of Introduction to the Theory of Computation by Michael Sipser.
The presentation there is a little more formal, but we’ll use the same notation so it might be useful to check that out for additional examples.
Problems
In lecture 1 we used Cantor’s Theorem to show that there are problems that can’t be solved. In that lecture, we defined a problem for every set.
If \(A\) is a set of strings, there is the problem problem of deciding whether a given input is in \(A\) or not.
Examples: \[
A = \{w \in \mathrm{Strings}: w \text{ is a palindrome}\},
\]
\[
A = \{w: w \text{ is a C program with no syntax errors}\}.
\]
Definitions
An alphabet, \(\Sigma\) is a non-empty, finite, set of symbols.
A string \(w\) over an alphabet \(\Sigma\) is a finite (0 or more) sequence of symbols from \(\Sigma\).
The set of all strings is denoted \(\Sigma^*\). (Before now, we’ve been calling it \(\mathrm{Strings}\)).
A language is any subset of \(\Sigma^*\).
Denote the empty string by \(\epsilon\) and note that it is the unique string with length \(0\).
More definitions
Let \(x, y \in \Sigma^*\) be strings, \(A, B \subseteq\Sigma^*\) be languages, and \(n \in \mathbb{N}\) be a natural number
Solution
\(\epsilon\).
Solution
\(\{\epsilon\}\).
- Let \(A^* = A^0 \cup A^1 \cup A^2 \cup A^3 \cup ... = \bigcup_{i \in \mathbb{N}}A^i\)
Generated by...
A while ago we studied what it meant for a set to be generated from \(B\) by the functions in \(F\).
Question. How would you generate \(\Sigma^*\)?
Solution
Where \(\texttt{concat}(x, y) = xy\)
Example - English
\(\Sigma = \{a, b, c,...,z\}\)
\(\Sigma^* = \{\epsilon, a, aa, ab, ac,...,ba,...,aaa,...\}\)
\(\mathrm{English} \subseteq\Sigma^*\)
Example - Even
\(\Sigma = \{0,1\}\)
\(\Sigma^* = \{\epsilon, 0,1,00,01,...\}\)
\(\mathrm{Even} = \{w \in \Sigma^*: w \text{ has an even number of 1s}\}\)
Alphabet
Any finite set works for the alphabet! However, to make things simple, we’ll usually take the alphabet to be \(\Sigma = \{0,1\}\), or \(\{a, b\}\).
The Problem (again)
Given a language \(A\) over an alphabet \(\Sigma\), come up with a program that decides whether a given string \(x \in \Sigma^*\) is in \(A\) or not.
Deterministic Finite Automata
What is a program?
To talk formally about computation it’s important to specify a model of computation.
DFAs
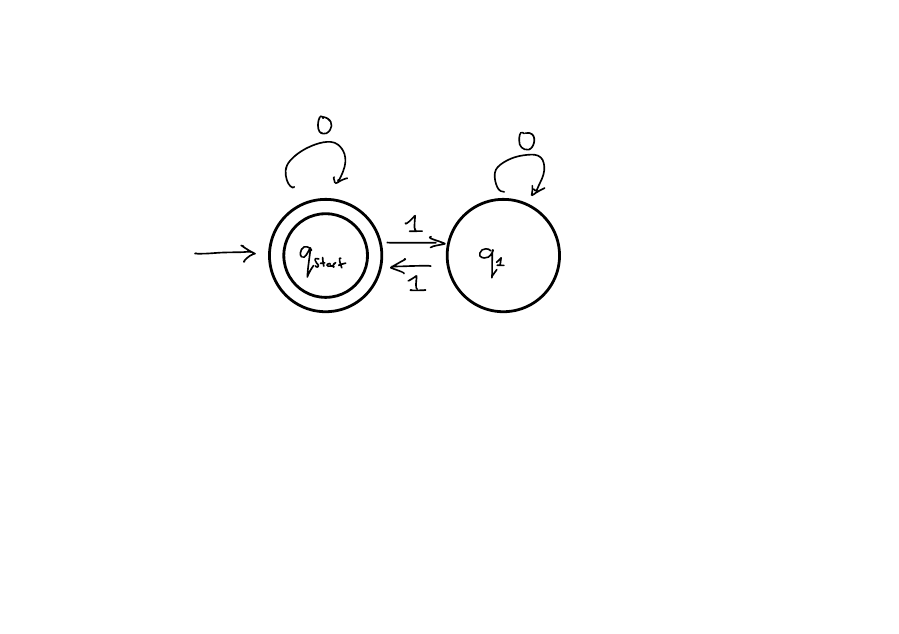
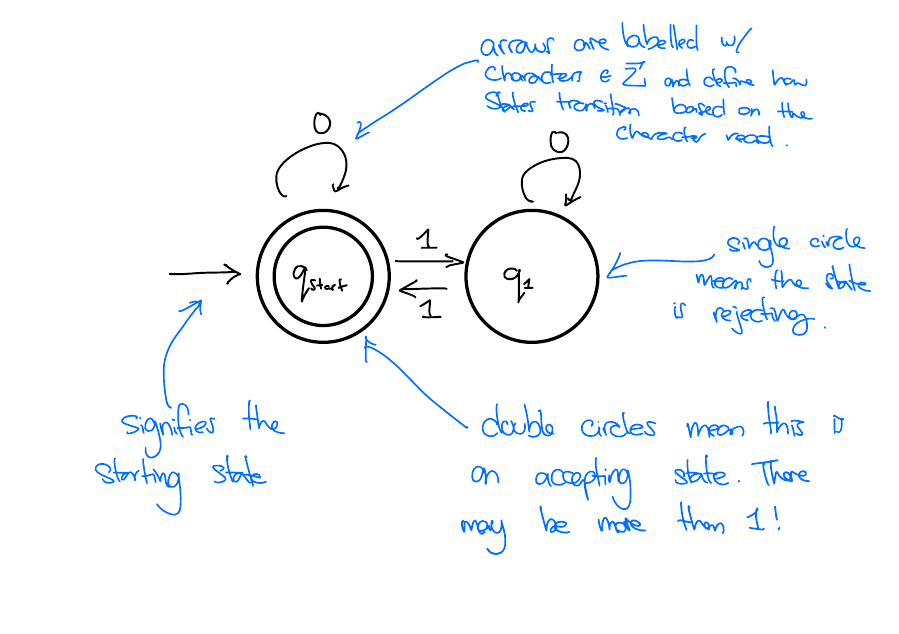
DFAs are one model of computation. They look like this.
![]()
A single DFA corresponds to what we think of as a program.
Computation of a DFA
Input: a string \(w \in \Sigma^*\).
Output: accept/reject.
The DFA starts at a predefined start state.
The DFA reads in the input string one character at a time. Depending on the character read and the current state, the DFA deterministically moves to a new state.
When it has read the entire string, the DFA will be in some state. If that state is one of the accept states, the DFA accepts. Otherwise, the DFA rejects.
![]()
Language of a DFA
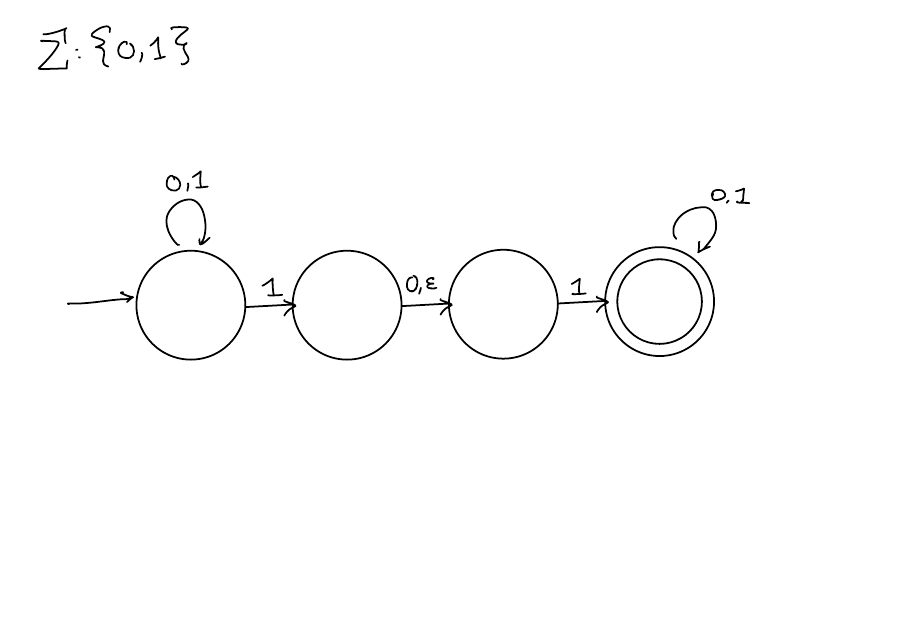
Let \(M\) be a DFA, the language of a DFA, denoted \(L(M)\), is the set of strings \(w \in \Sigma^*\) such that \(M\) accepts \(w\).
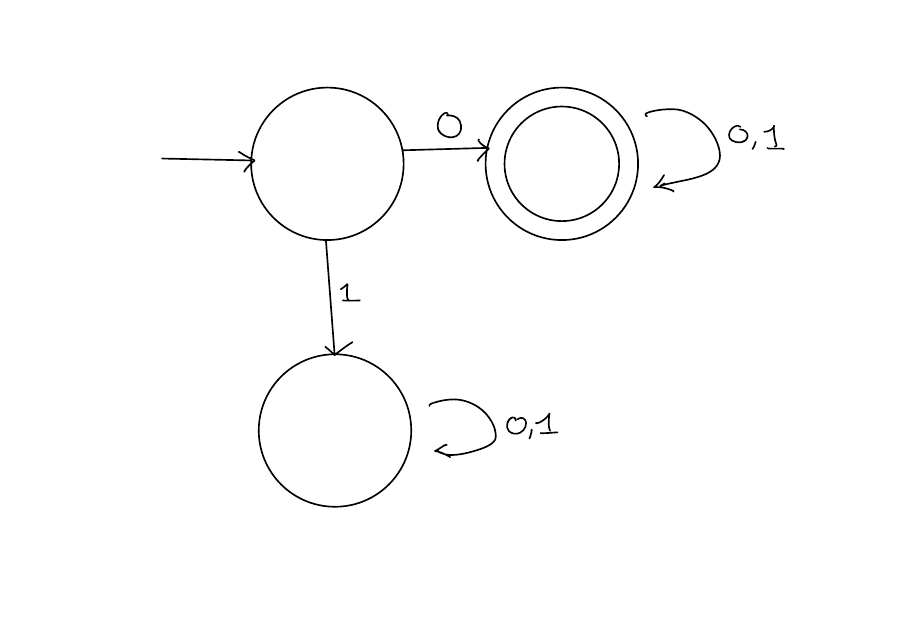
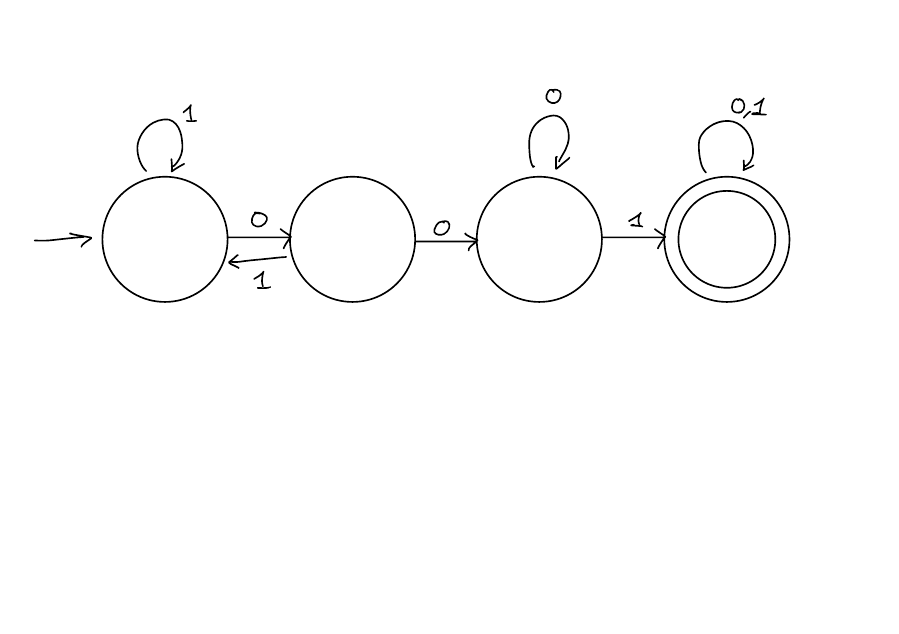
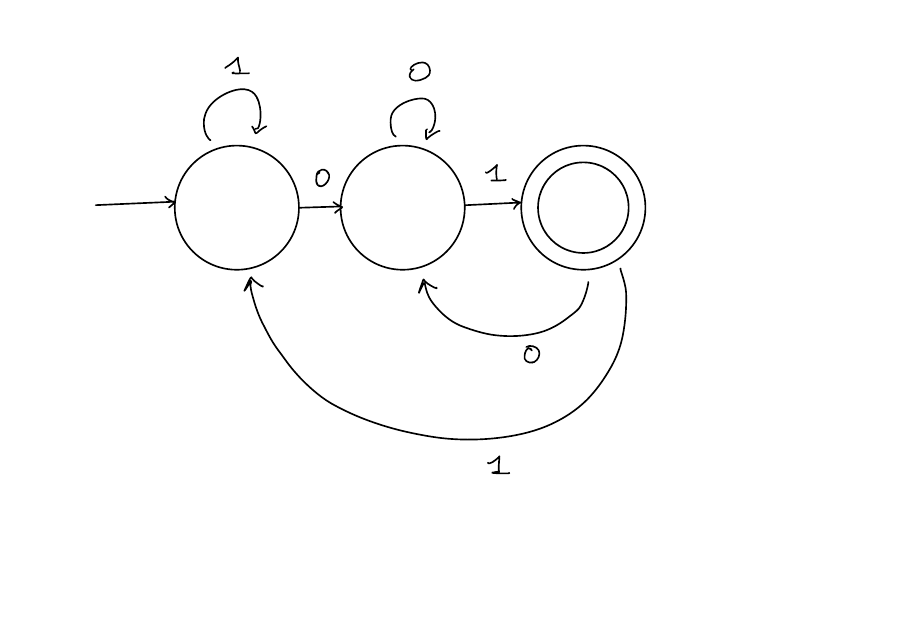
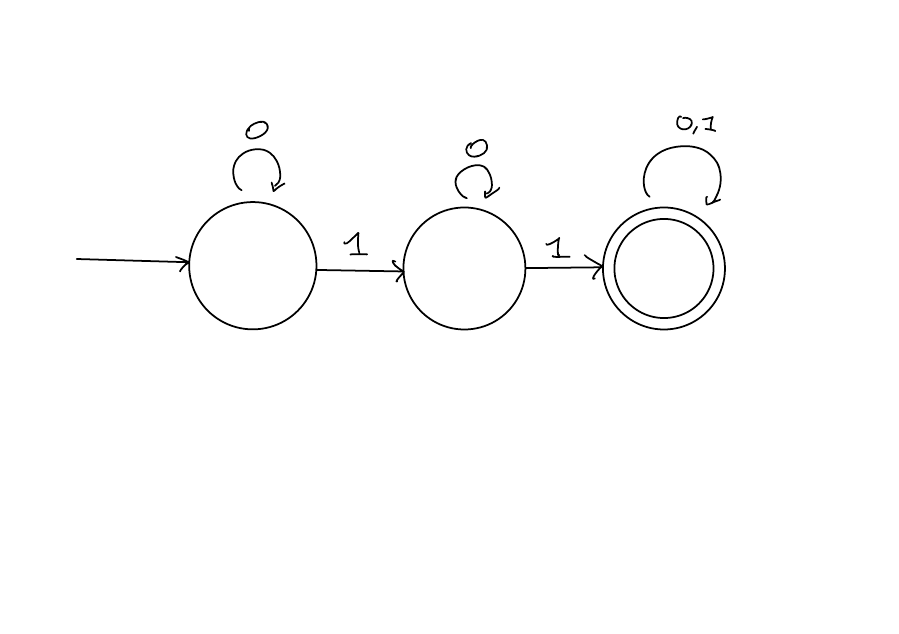
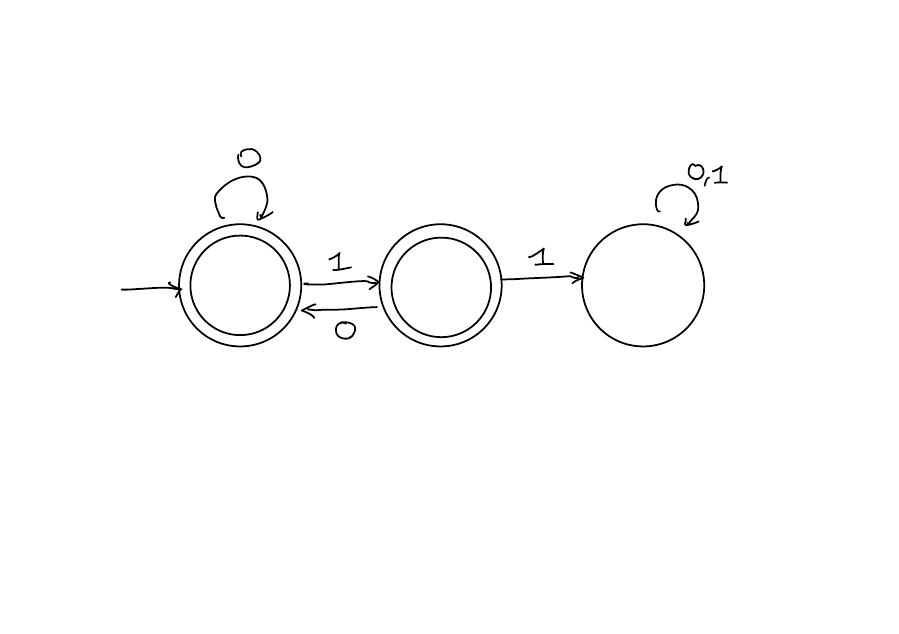
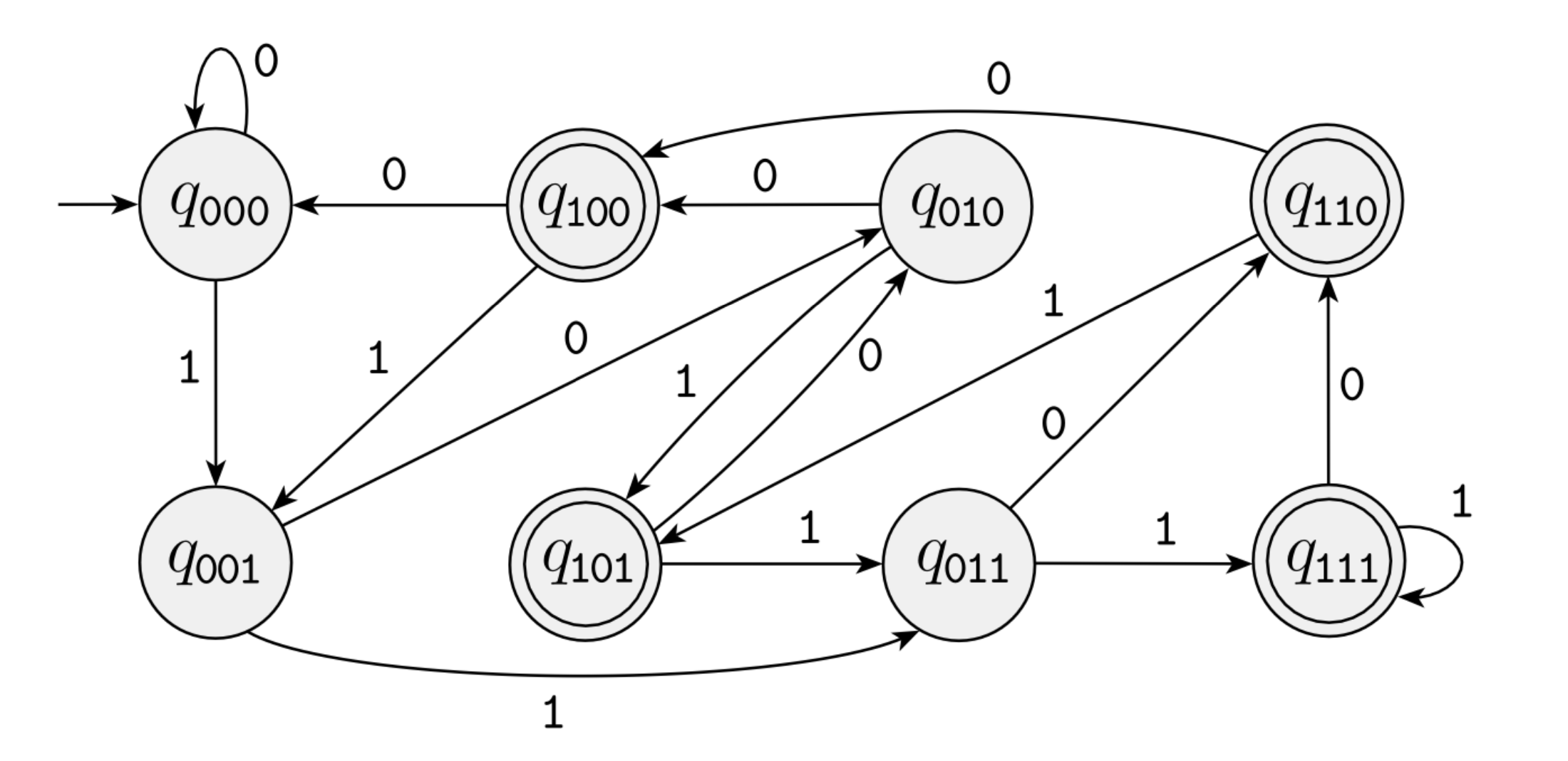
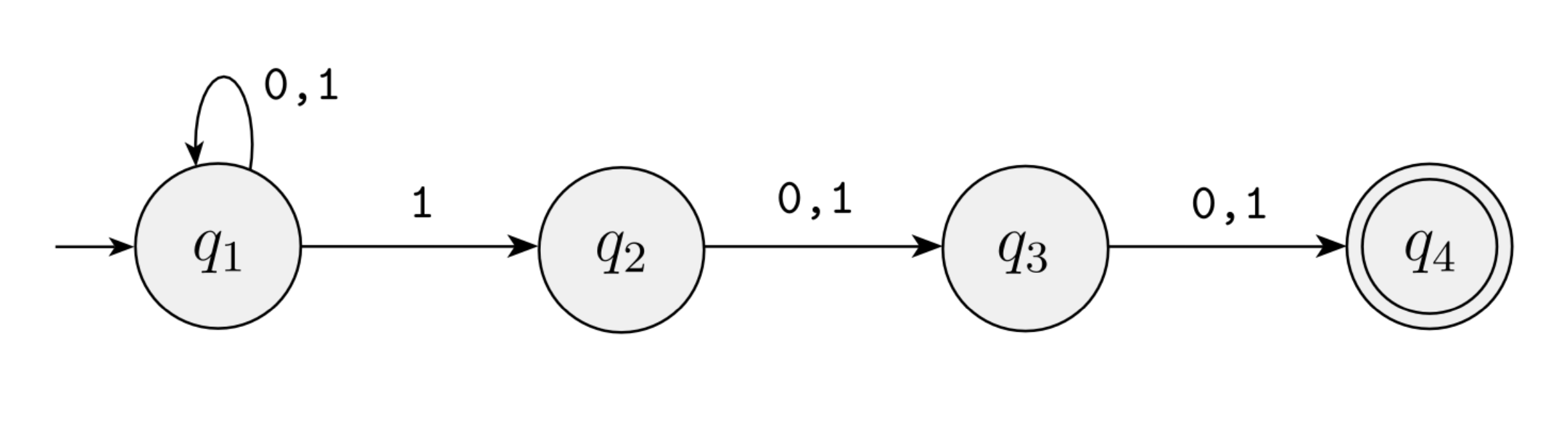
Example
![]()
Example
![]()
Example
![]()
Example
![]()
DFAs
Deterministic. Given the current state and character read, the next state is always the same.
Finite. There are a finite number of states.
States are analogous to “memory”, since we can store information about the input by transitioning to different states.