Students
PhD and MSc students

David Acuna
PhD Student (2018 - )
Tianshi Cao
MSc Student (2019 - )
Harris Chan
PhD Student (2019 - )Co-supervised with Jimmy Ba

Wenzheng Chen
PhD Student (2017 - )Co-supervised with Kyros Kutulakos

Sasha Doubov
MSc Student (2020 - )
Jun Gao
PhD Student (2020 - )
Amlan Kar
PhD Student (2017 - )
Seung Kim
PhD Student (2017 - )
Gary Leung
MSc Student (2020 - )
Tianxing Li
MSc Student (2020 - )
Andrew Liao
PhD Student (2019 - )
Huan Ling
PhD Student (2021 - )
Jonah Philion
PhD Student (2019 - )
Frank Shen
MSc Student (2019 - )
Masha Shugrina
PhD Student (2017 - )Co-supervised with Karan Singh

Towaki Takikawa
PhD Student (2020 - )Co-supervised with Alec Jacobson

Tingwu Wang
PhD Student (2016 - )Co-supervised with Jimmy Ba

Zian Wang
PhD Student (2019 - )
Xinkai Wei
MSc Student (2019 - )
Kevin Xie
MSc Student (2019 - )Co-supervised with Florian Shkurti

Xiaohui Zeng
MSc Student (2018 - )Amlan Kar
Amlan started his PhD in Sept 2017.Undergraduate students
|
|
Nadia Li 4th year undergraduate, UofT Oct 2020 - |

|
Sandeep Routray 4th year undergraduate, IIT Kanpur July 2020 - |

|
Avik Pal 4th year undergraduate, IIT Kanpur Jan 2020 - |

|
Hirotaka Ishihara 4th year undergraduate, UofT Dec 2019 - |
|
|
Jiongtian Guo 4th year undergraduate, UofT May 2020 - |

|
Chen Cui 4th year undergraduate, UofT May 2020 - |

|
Ziyue Xu 4th year undergraduate, UofT May 2020 - |
Visiting students

|
Anyi Rao PhD student at CHUK Sept 2020 -- - |
Past postdocs

|
|
Makarand Tapaswi Postdoc (now postdoc at INRIA) Sept 2016 - Dec 2018 |
Past graduate students

|
|
Hang Chu Sept 2016 - April 2020 Now at Autodesk |

|
|
Atef Chaudhury Graduated with MSc (now at Google) Sept 2017 - April 2019 |

|
|
Kevin Shen Graduated with MSc (now at Layer6) Sept 2017 - Jan 2019 |

|
|
Jiaman Li Graduated with MSc (now Phd student at University of South California) Sept 2017 - Jan 2019 |

|
|
Chaoqi Wang Graduated with MSc (now Phd student at University of Chicago) Sept 2017 - Jan 2019 |

|
|
Kaustav Kundu Graduating with PhD (now at Amazon) Sept 2015 - May 2017 Co-supervised with Raquel Urtasun |

|
|
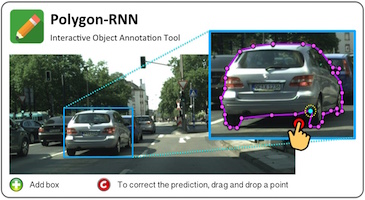
Lluis Castrejon Graduated with MSc (now at University of Montreal) Sept 2015 - May 2017 Co-supervised with Raquel Urtasun Lluis CastrejonLluis worked on semi-automatic instance segmentation. Our CVPR'17 paper on this topic received Best Paper Honorable Mention.Publications
|

|
|
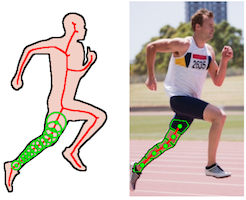
Tom Lee Graduated with PhD (now at LTAS Technologies Inc) Sept 2011 - March 2016 Co-supervised with Sven Dickinson Tom LeeTom is a 4th year PhD student and is currently doing a 8-month internship in a Toronto-based company LTAS Technologies Inc. Tom works on mid-level vision: grouping superpixels to form symmetric parts using a discriminative (trained) approach, and a learning framework for grouping superpixels into object proposals using several Gestalt-like cues (symmetry, closure, homogeneity of appearance). For the former, he showed how to learn with parametric submodular energies. His primary supervisor is Prof. Sven Dickinson.Publications
|





|
|
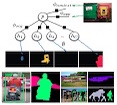
Yukun Zhu Graduated with MSc (now at Google) Sept 2015 - Jan 2016 Co-supervised with Raquel Urtasun and Ruslan Salakhutdinov Yukun ZhuYukun's research was in two domains: object class detection and vision-language integration. His approach published at CVPR'15 significantly outperformed previous state-of-the-art in detection on PASCAL VOC.Publications
|






|
|
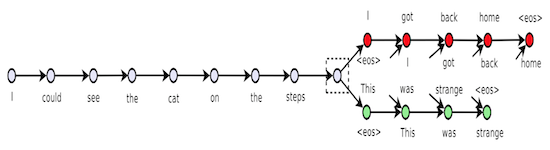
Ivan Vendrov Graduated with MSc (now at Google) Sept 2015 - Jan 2016 Co-supervised with Raquel Urtasun
Ivan's masters thesis was on the topic of semantic visual search.
close window
Publications
|

|
|
Ziyu Zhang Graduated with MSc (now at Snap Inc) Sept 2015 - April 2016 Co-supervised with Raquel Urtasun Ziyu ZhangZiyu's masters' thesis was on instance-level object segmentation in monocular imagery.Publications
|


Past visiting graduate students

|
Didac Suric MSc student at UPC (now at Columbia University) Sept 2018 - |

|
Bo Dai PhD student, Chinese University of Hong Kong (now postdoc at MIT) Sept - Dec 2017 |

|
Enric Corona MSc student, UPC in Barcelona (now PhD at UPC) May - Dec 2017 |

|
|
Xavier Puig Fernandez PhD student, MIT Jan-March, 2016
Xavier is visited the group two times, once in Nov 2015, and from Jan to March, 2016. We are working on the problem of video to text alignment.
|
Co-supervised with Raquel Urtasun:

|
|
Urban Jezernik PhD student, University of Ljubljana Jan-April, 2016
Urban visited the group from Jan to April, 2016. We were working on the problem of music generation.
|
|
|
|
Makarand Tapaswi PhD student, KIT (now a postdoc in our group) Sept-Dec, 2015
Makarand visited for three months in 2015, and has joined our group as a postdoc in the fall of 2016.
Publications
|

|
Edgar Simo-Serra PhD student, UPC in Barcelona (now a postdoc at Tokyo University) Summer 2013, 2014
Edgar visited the group twice. During his first visit (to TTI-C) he was working on clothing parsing in fashion photographs. On this topic he published a first-author paper at ACCV'14. In his second visit (to UofT), he worked on predicting how fashionable / stylish someone looks on a photograph, and suggest ways to help the user to improve her/his "look". This resulted in a
first-author CVPR'15 paper. The paper got significant international press coverage in major news and fashion media such as New Scientist, Quartz, Wired, Glamour, Cosmopolitan, Elle and Marie Claire (see project page for more details). Edgar gave several interviews for the press, including an appearance on Spanish television (minutes 15:12 to 16:43) and radio (minutes 16:10 to 20:43). Yahoo News, Canada, featured a full photo of him in one of my favorite press articles on the subject. Publications
|



|
|
Roozbeh Mottaghi PhD student, UCLA (now a Research Scientist at AI2) Summer 2012, 2013
Roozbeh visited the group several times, working on the topic of object class detection. His work resulted in several state-of-the-art detectors. He published two first-author and two second-author CVPR papers (CVPR'13 and '14), as well as a first-author T-PAMI publication. Roozbeh went to do a postdoc with Prof. Silvio Savarese at Stanford and is now a Research Scientist at AI2. Publications
|




|
|
Liang-Chieh Chen PhD student, UCLA (now at Google) Summer 2013
Liang-Chieh ("Jay") worked on weakly-labeled segmentation: getting accurate object segmentation given a ground-truth 3D bounding box as available in the KITTI dataset. His method improved significantly over existing grab-cut type of approaches, and even outperformed MTurkers (compared to accurate in-house annotations). Jay authored a first-author paper at CVPR'14.
Publications
|


|
|
Abhishek Sharma PhD student, UMD (now at Apple) Summer 2012
Abhishek worked on holistic scene parsing by exploiting image captions. Making use of textual information for visual parsing is important for, e.g., robotics applications where an automatics system interacts with a human user. Abhishek co-authored a CVPR'13 paper.
Publications
|
Past undergraduate students
|
|
Bowen Chen 3rd year undergraduate, UofT (now Msc at Columbia University) Jan 2019 - Sept 2020 |

|
Maciej Kowalski 4th year undergraduate, UofT (now at University of Edinburgh) Dec 2019 - May 2020 |
|
|
Jinchen Xuan 4th year undergraduate, Peking University June 2019 – Nov 2019 |
|
|
Zhaocong (Justin) Yuan 4th year undergraduate, UofT Sept 2019 -- May 2020 |

|
Jordi Fortuny Profitos 4th year undergraduate, UPC Thesis, Sept 2018 - |

|
Eric Guisado Bandres 4th year undergraduate, UPC Thesis, Sept 2018 - |
|
|
Rafel Palliser Sans 4th year undergraduate, UPC Thesis, Sept 2018 - |
|
|
Louis Clergue 4th year undergraduate, UPC Thesis, Feb 2019 - |
|
|
Tianshi Cao 4th year undergraduate, UofT (now Msc at UofT) Thesis, Sept 2018 - Aug 2019 |

|
Xi Yan 4rd year undergraduate, UofT (now at Stanford University) May 2019 - Dec 2019 |

|
Yuhao Zhou 3rd year undergraduate, UofT Jan 2017 - 2019 |
|
|
Zian Wang 4th year undergraduate, Tsinghua University (now PhD at UofT) July 2018 -- Nov 2018 |
|
|
Liren Chen 3rd year undergraduate, Tsinghua University Summer 2017 |

|
Ching-Yao Chuang 4th year undergraduate, National Tsinghua University of Taiwan (now PhD at MIT) July - Nov 2017 |
|
|
Zheng Wu 3rd year undergraduate, Shanghai Jiao Tong University Summer 2017 |

|
Kefan (Arthur) Chen 4th year undergraduate, UofT /(now at Google) Capstone project, Sept 2017 - May 2018 |

|
Tiantian Fang 4th year undergraduate, UofT (now at UIUC) Sept 2017 - Jan 2018 |
|
|
Wesley Heung 4th year undergraduate, UofT Thesis, Sept 2017 - May 2018 |
|
|
Daiqing Li 4th year undergraduate, UofT (now at NVIDIA) Capstone project, Sept 2017 - May 2018 |

|
Juan Morales Vega 4th year undergraduate, UPC in Barcelona Feb - June 2017 |
|
|
Haokun Liu 3rd year undergraduate, Peking University (now at NYU) Feb - June 2017 |
|
|
Ge (Olga) Xu 3rd year undergraduate, UofT Summer 2016 (USRA) |

|
Kevin Kyunghwan Ra 4th year undergraduate, UofT (now at McMaster University) 2016 |

|
Vasu Sharma 3rd year undergraduate, IIT Kanpur Summer 2016, co-supervised with Raquel Urtasun |
|
|
Amlan Kar 3rd year undergraduate, IIT Kanpur (now doing PhD with me at UofT) Summer 2016, co-supervised with Raquel Urtasun |

|
Erin Grant 4th year undergraduate, UofT (now a PhD student at UC Berkeley) Jan-April, 2016 |

|
Seung Wook Kim 4th year undergraduate, UofT (now doing MSc with me at UofT) Jan-April, 2016 |

|
Huazhe Xu 4th year visiting student from Tsinghua University (now a PhD student at UC Berkeley) Sep 2015 - Dec 2015, co-supervised with Raquel Urtasun |

|
Boris Ivanovic 4th year undergraduate, UofT (now a MSc student at Stanford University) Sep 2015 - May 2016, co-supervised with Raquel Urtasun |

|
Tamara Lipowski 4th year undergraduate, UofT (now a MSc student at University of Salzburg) Jan-April, 2016 |

|
Zexuan (Aaron) Wang 4th year undergraduate, UofT (now at Qumulo Inc) Sept 2015 - April 2016, co-supervised with Raquel Urtasun |
|
|
Jurgen Aliaj 2nd year undergraduate, UofT (now a MSc student at UofT) Summer 2015 (USRA) |

|
Andrew Berneshawi 4th year undergraduate, UofT (now at Amazon, Seattle) CSC494, Winter 2015
Andrew worked on road estimation as part of a semester-long project course (CSC494). His approach ranked second on KITTI's road classification benchmark (entry: NNP, time stamped: June 2015).
close window
|

|
Chenxi Liu 4th year undergraduate, Tsingua University (now a PhD student at Johns Hopkins University) Summer 2014, co-supervised with Raquel Urtasun
Chenxi worked on the problem of apartment reconstruction in 3D from rental data (monocular imagery and floor-plan). His work resulted in a joint first-author oral CVPR'15 paper. He gave a talk at CVPR and did a great job (you can check his performance below).
close window
Publications
|



|
Yinan Zhao 4th year undergraduate, Tsingua University (now a PhD student at UT Austin) Summer 2014, co-supervised with Raquel Urtasun |

|
Chen Kong 4th year undergraduate, Tsingua University (now a PhD student at CMU) Summer 2013, co-supervised with Raquel Urtasun
Chen worked on 3D indoor scene understanding by exploiting textual information. His work resulted in one first-author and another co-authored CVPR'14 paper, and he co-authored an oral paper at BMVC'15. Publications
|

|
Jialiang Wang 4th year undergraduate, UofT (now a PhD student at Harvard University) Summer 2014 (USRA), co-supervised with Sven Dickinson |

|
Uri Priel 3rd year undergraduate, UofT Summer 2014 (USRA), co-supervised with Sven Dickinson |

|
Kamyar Seyed Ghasemipour 2nd year undergraduate, UofT (now a MSc student at UofT) Summer 2014 (USRA), co-supervised with Suzanne Stevenson and Sven Dickinson
Kamyar worked on unsupervised word-sense disambiguation of captioned images. He
won a research video competition (video)
held for the Undergraduate Summer Research Program at UofT.
close window
|