CSC 420: Introduction to Image Understanding
Undergraduate CourseFall 2014
Everyone has large photo collections these days. How can you intelligently find all pictures in which your dog appears? How can you find all pictures in which you are frowning? Can we make cars smart, e.g., can the car drive you to school while you finish your last homework? How can a home robot understand the environment, e.g., switch on a tv when being told so and serve you dinner? If you take a few pictures of your living room, can you reconstruct it in 3D (which allows you to render it from any new viewpoint and thus allows you to create a "virtual tour" of your room)? Can you reconstruct it from one image alone? How can you efficiently browse your home movie collection, e.g. find all shots in which Tom Cruise is chasing a bad guy?
Course Overview
Prerequisites: A second year course in data structures (e.g., CSC263H), first year calculus (e.g., MAT135Y), and linear algebra (e.g., MAT223H) are required. Students who have not taken CSC320H will be expected to do some extra reading (e.g., on image gradients). Matlab will extensively used in the programming excercises, so any prior exposure to it is a plus (but not a requirement).
Course Information
-
Time and Location
Fall 2014
Day: Tuesday and Thursday Time: 3pm-4pm Room: BA2185 Tutorials Room: BA2185Instructor
Sanja Fidler
Email: fidler@cs... Homepage: http://www.cs.utoronto.ca/~fidler Office hours: Tuesday at 1.20-2.50pm, or by
appointment (send email)
Information Sheet
The information sheet for the class is available here.
Programming Language(s)
You are expected to do some programming assignments for the class. You can code in either Matlab, Python or C. However, in class we will provide the examples and functions in Matlab. Note also that most Computer Vision code online is in Matlab so it's useful to learn it. Knowing C is only a plus since you can interface your C code to Matlab via "mex".
Please make sure you have access to MATLAB with the Image Processing Toolbox installed.
Forum
This class uses piazza. On this webpage, we will post announcements and assignments. The students will also be able to post questions and discussions in a forum style manner, either to their instructors or to their peers.
Please sign up here in the beginning of class.
Textbook
We will not directly follow any textbook, however, we will require some reading in the textbook below. Additional readings and material will be posted in the schedule table as well as the resources section.
-
Website
"Computer Vision: Algorithms and Applications"
Richard Szeliski
Springer, 2010
The textbook is freely available online and provides a great resource for introduction to computer vision.
We will be reading the Sept 3, 2010 version.
Requirements and Grading
Each student is expected to complete five assignments which will be in the form of problem sets and programming problems, and complete a project.
Assignments
Assignments will be given every two weeks. They will consist of problem sets and programming problems with the goal of deepening your understanding of the material covered in class. All solutions and programming should be done individually. There will be five assignments altogether, each worth 10% of the final grade.
Submission: Solutions to the assignments should be submitted through CDF. The preferred format is PDF, but we will also accept Word. Unless stated otherwise in the Assignments' instructions include the code (for exercises that ask for code) within the solution document. An ideal example of how the code can be included can be found here. We also don't mind if you print-screen your matlab functions and include the pictures as long as they are of good quality to be read. If you are using Matlab's built-in functions within your code you should not include them. But include all your code.
Deadline: The solutions to the assignments should be submitted by 11.59pm on the date they are due. Anything from 1 minute late to 24 hours will count as one late day.
Lateness policy: Each student will be given a total of 3 free late days. This means that you can hand in three of your assignments one day late, or one assignment three days late. It is up to you to make a good planning of your work. After you have used your 3 day budget, your late assignments will not be accepted.
Plagiarism: We take plagiarism very seriously. Everything you hand in to be marked, namely assignments and projects, must represent your own work. Read How not to plagiarize.
Project
Each student will be given a topic for the project. You will be able to choose from a list of projects, or propose your own project which will need to be discussed and approved by your instructor. You will need to hand in a report which will count 30% of your grade. Each student will also need to present and be capable to defend his/her work. The presentation will count 20% of the grade.
Assignments | 50%(5 assignments, each worth 10%) |
Project | 50% (report: 30%, presentation: 20%) |
Syllabus
The course will cover image formation, feature representation and detection, object and scene recognition and learning, multi-view geometry and video processing. Since Kinect is popular these days, we will also try to squeeze recognition with RGB-D data into the schedule.
| Image Processing |
|---|
Linear filters |
Edge detection |
| Features and matching |
Keypoint detection |
Local descriptors |
Matching |
Low-level and Mid-level grouping |
Segmentation |
Region proposals |
Hough voting |
Recognition |
Face detection and recognition |
Object recognition |
Object detection |
Part-based models |
Image labeling |
Geometry |
Image formation |
Stereo |
Multi-view reconstruction |
Kinect |
Video processing |
Motion |
Action recognition |
Schedule
| Date | Topic | Reading | Slides | Additional material | Assignments |
|---|---|---|---|---|---|
| Sept 11 | Course Introduction | lecture1.pdf | Tutorial: intro to Matlab | ||
| Image Processing | |||||
| Sept 11 | Linear Filters | Szeliski book, Ch 3.2 | lecture2.pdf | code: finding Waldo, smoothing, convolution | |
| Sept 16 | Edge Detection | Szeliski book, Ch 4.2 | lecture3.pdf | code: edges with Gaussian derivatives | |
| Sept 18 | Image Pyramids | Szeliski book, Ch 3.5 | lecture4.pdf | Assignment 1: due Sept 27, 11.59pm, 2014 | |
| Sept 23 | State-of-the-art Edge Detection | P. Dollar, C. Zitnick, Structured Forests for Fast Edge Detection, ICCV'13 | lecture5.pdf | code: Structured Edge Detection Toolbox by Dollar et al. | |
| Features and Matching | |||||
| Sept 25 | Keypoint Detection: Harris Corner Detector | Szeliski book, Ch 4.1.1 pages: 209-215 | lecture6.pdf | ||
| Sept 30 | Keypoint Detection: Scale Invariant Keypoints | Szeliski book, Ch 4.1.1 pages: 216-222 | lecture7.pdf | ||
| Oct 2 | Local Descriptors: SIFT, Matching | Szeliski book, Ch 4.1.2 Lowe's SIFT paper | lecture8.pdf | code: compiled SIFT code, VLFeat's SIFT code | Assignment 2: due Oct 12, 11.59pm, 2014 |
| Oct 7 | Robust Matching, Homographies | Szeliski book, Ch 6.1 | lecture9.pdf | ||
| Oct 9 | Homographies continued | Lec. 9 cont. | code: Soccer and screen homography | Projects: due Dec 10, 11.59pm, 2014 | |
| Geometry | |||||
| Oct 14 | Camera Models | Szeliski, 2.1.5, pp. 46-54Zisserman & Hartley, 153-158 | lecture10.pdf | ||
| Oct 16 | Camera Models | Lec. 10. cont. | Assignment 3: due Oct 26, 11.59pm, 2014 | ||
| Oct 21 | Stereo: Parallel Optics | lecture11.pdf | code: Yamaguchi et al. | ||
| Oct 23 | Stereo: Parallel Optics | Lec. 11 cont. | |||
| Oct 28 | Stereo: General Case | Szeliski book, Ch. 11.1 Zisserman & Hartley, 239-261 | lecture12.pdf | ||
| Recognition | |||||
| Oct 30 | Fast Retrieval | Sivic & Zisserman, Video Google | lecture13.pdf | Assignment 4: due Nov 13, 11.59pm, 2014 | |
| Nov 4 | Recognition: Overview | Grauman & Leibe, Visual Object Recognition | lecture14.pdf | ||
| Nov 6 | Recognition: Today | Lec. 14 cont. | |||
| Nov 11 | Recognition: History | Mundy, Object Recognition in the Geometric Era | lecture15.pdf | ||
| Nov 13 | Recognition: History 2 | Lec. 15 cont. | Jialiang Wang's Tutorial on classification | ||
| Nov 20 | Implicit Shape Model | B. Leibe et al., Robust Object Detection with Interleaved Categorization and Segmentation | lecture16.pdf | Assignment 5: due Nov 30, 11.59pm, 2014 | |
| Nov 25 | The HOG Detector | HOG paper | lecture17.pdf | ||
| Nov 27 | Deformable Part-based Model, Segmentation | DPM paper | lecture18.pdf lecture19.pdf | ||
| Dec 2 | All You Wanted To Know About Neural Networks | Invited lecture: Alex Schwing | lecture20.pdf | ||
Feedback About Class
Whether you are enrolled in the class or just casually browsing the webpage, please leave feedback about the class / material. You can do it here. Thanks!
Assignment Solutions: Hall of Fame
Assignment 1: Seam Carving
The exercise was to remove horizontal and/or vertical seams, i.e. paths with the smallest sum of gradients. We followed Avidan and Shamir's "Seam Carving for Content-Aware Image Resizing" paper.








Assignment 2: Window Detection
The exercise was to detect all frontal windows in a given image. Four students submitted solutions, all were great and spot on. Here we are showing the top two competitors, along with their accuracy measured with the F1-score. Huazhe won with 92.3% and also has the least tuneable parameters -- very impressive. Mian achieved a higher recall (detected all windows!) but a slightly lower precision. Congrats to Huazhe and Mian!




Assignment 3: Drive a Car in Monocular Images
In this extra credit exercise, a monocular image is given along with the intrinsic camera parameters. We also know that the image plane is orthogonal to the ground. The goal is to realistically render a 3D CAD model in the scene. We got some great renderings! The best videos have been created by Andrew Berneshawi, congrats!
Andrew George Berneshawi
Mian Wei
Wonjoon Goo
Huazhe (Harry) Xu
Amy Ka-Wai Yang

Ilia Samsonov

Assignment 4: Car Segmentation
We held a competition in car segmentation. Input is a stereo image pair and the output is an image labeling of car vs background. 25 image pairs with ground-truth were provided for training, while test had 20 image pairs. The best, and very impressive, performance 71.1% was achieved by Andrew Berneshawi, followed by Huazhe Xu (67.4%) and Stanislav Ivashkevich (66.3%). Performance is measured as intersection-over-union between GT car pixels and predicted car pixels. Congrats to all participants! Below we are showing a few example segmentations for top 5 participants.
-
Images


-
Ground-truth


-
Andrew Berneshawi
Accuracy: 71.1%


-
Huazhe Xu
Accuracy: 67.4%


-
Stanislav Ivashkevich
Accuracy: 66.3%


-
Mian Wei
Accuracy: 57.0%


-
Diego Santos
Accuracy: 53.2%


Projects
We had five possible projects with the option of coming up with own idea for the project. Below are some of the best results.
Project 1
For this project three clips from the TV series Buffy The Vampire Slayer were given. The task was to compute shots (chunks of video where camera motion is smooth), determine which shots were night or day, detect and track faces, determine which faces were a close-up, and which face belonged to Buffy. Extra credit was to determine if Buffy was talking or not.
-
Authors
Ching Fung Yung (main)
John Jun Shang
Project 2
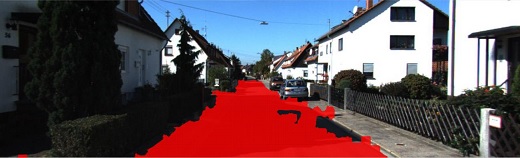
This project was tackling subproblems in the domain of autonomous driving. We worked with stereo pair data from the KITTI dataset, the road segmentation benchmark. Ground-truth labels were available for road segmentation and objects (in 3D) for the training subset, but not for test. The tasks were: road classification, object detection and viewpoint classification, 3D bounding box estimation.
-
Authors
Andrew Berneshawi
Emma Hsueh






Project 3
The goal of this project was to analyze video clips of broadcast news. The tasks were: shot detection, detect logo in the video automatically (without knowledge of which logo and where it appears in the clip), detect and track faces, classify faces into male/female.
-
Authors
Marisol Miel Aguila
Ilia Samsonov
-
Authors
Wonjoon Goo (did most)
Danilo Nogueira Rodrigues
System Overview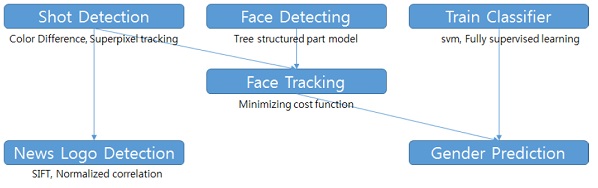
Resources
- Forsyth and Ponce, Computer Vision: A Modern Approach
- Richard Hartley and Andrew Zisserman, Multiple View Geometry in Computer Vision
- Kristen Grauman and Bastian Leibe, short book on Visual Object Recognition
- Christopher M. Bishop, Pattern Recognition and Machine Learning
- Tom Mitchell, Machine Learning
- Short tutorial on getting started with Matlab
- CV online: wiki with computer vision concepts
- Li Fei-Fei, Rob Fergus, Antonio Torralba, Tutorial on Recognizing and Learning Object Categories
- Andrew Moore, Tutorial on Support Vector Machines
- Sebastian Nowozin, Christoph H. Lampert, Structured Learning and Prediction in Computer Vision (advanced Machine Learning Tutorial)
- Tutorial on writing fast Matlab code
- OpenCV library: open source computer vision library (c++)
- VLfeat: open source computer vision library (Matlab, c)
- LIBSVM: A Library for Support Vector Machines (Matlab, Python)
- Structured Edge Detection Toolbox: Very fast edge detector (up to 60 fps) with high accuracy
- Object detection code with Deformable Part-based Models
- Caffe: Deep learning features for image classification
- Bundler: Structure from Motion (SfM) for Unordered Image Collections
- SLIC superpixels: Very fast superpixel code
- UCM superpixels: Accurate superpixels
- Selective Search: code for computing bottom-up region proposals
- PASCAL VOC: Object recognition dataset
- KITTI: Autonomous driving dataset
- Reconstruction Meets Recognition Challenge (RMRC): Indoor recognition with RGB-D data
- LabelMe: Open image annotation tool
- ImageNet: Large-scale object dataset
- ReKognition API: Demo for face recognition and detection, image classification
- Photosynth: View the world in 3D
- Google goggles app
- Clothing parser demo by Tamara Berg's group
- A list of online computer vision demos
- The Computer Vision Industry, a list of CV companies maintained by David Lowe